AI-Generated Marketing Content: A Content-Type Taxonomy and Quality-Control Framework
A structured practitioner reference for marketing professionals producing or overseeing AI-generated content — organized by content type rather than tool, covering automation viability ratings, tiered QC requirements, and known failure modes for each of six distinct content categories.
The Implementation Gap: Why 91% Adoption Produces 25% Results
According to Jasper's 2026 research, 91% of marketing teams now use AI for content. According to Averi, only 25% report meaningful business outcomes from it. That gap is not explained by tool quality, budget, or team size. It is explained by a structural decision problem: most practitioners make automation choices at the tool level — "we use ChatGPT" or "we use Jasper" — rather than at the content-type level.
The consequence is predictable: teams apply uniform automation to content that has sharply different automation viability, skip quality-control steps that are non-negotiable for certain content types, and then attribute poor outcomes to the tool rather than to the decision framework.
This guide is organized as a structured practitioner reference, not a narrative introduction to AI content. It covers six distinct content types, each evaluated for automation viability, required QC steps, and known failure modes. It also provides an automation decision matrix and a tiered QC checklist organized by content risk level. Use it as a working reference when deciding what to automate, how to review it, and where AI systematically fails.
Scope: What Qualifies as AI-Generated Marketing Content
For the purposes of this guide, AI-generated marketing content refers to text output produced or substantially drafted by a generative AI model for use in a marketing channel — including content that was human-prompted, human-edited, or assembled from AI-generated components. The defining characteristic is that the model contributed the primary draft.
Treating this as a single category — "AI content" — is the root cause of most failed implementations. The six types covered here differ enough in purpose, audience, factual requirements, brand sensitivity, and regulatory exposure that a single automation policy applied across all of them will reliably underserve some and over-invest in others.
What this guide covers:
- Long-form SEO content (blog posts, topic cluster articles, landing page copy)
- Ad copy (search headlines and descriptions, display copy, paid social copy)
- Email copy (subject lines, body copy, nurture sequences)
- Social copy (organic platform posts, caption variations, community responses)
- Product and catalog descriptions (e-commerce listings, SKU-level descriptions, feature summaries)
- Sales enablement assets (one-pagers, battlecards, email templates, proposal sections)
What this guide does not cover:
- AI-assisted analytics and reporting (separate capability category)
- Predictive bidding and programmatic decisioning (not content generation)
- AI image and video generation (distinct production workflow)
- Conversational AI and chatbot scripting (covered separately)
Content-Type Taxonomy: Six Types Mapped to Marketing Functions
The table below maps each content type to its primary marketing function, typical volume characteristics, and channel context. These mappings are the basis for the per-type evaluations that follow.
| Content Type | Primary Marketing Function | Typical Volume | Channel Context |
|---|---|---|---|
| Long-form SEO content | Organic search acquisition, topic authority | Low–medium (1–20 pieces/month) | Blog, resource hub, landing pages |
| Ad copy | Paid acquisition, conversion | High (dozens to hundreds of variants) | Search, display, paid social, shopping |
| Email copy | Nurture, retention, conversion | Medium–high (sequences, campaigns) | ESP / marketing automation |
| Social copy | Awareness, engagement, community | High (daily or near-daily posting) | LinkedIn, Instagram, X, Facebook |
| Product / catalog descriptions | Purchase enablement, SEO | Very high (hundreds to thousands of SKUs) | E-commerce, marketplace listings |
| Sales enablement assets | Pipeline acceleration, deal support | Low (high-value, deal-specific) | CRM, direct sales, proposals |
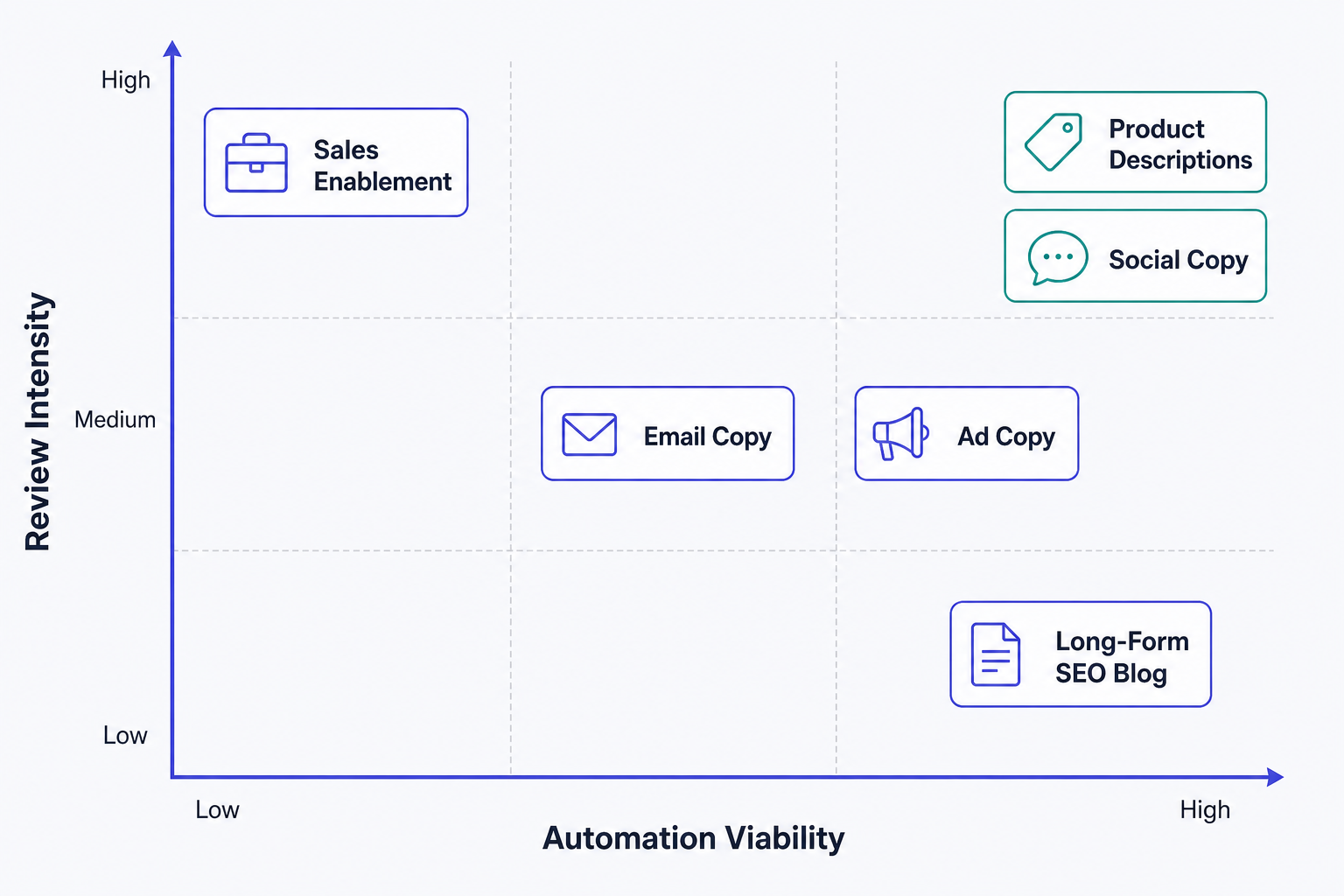
Per-Type Evaluation: Automation Viability, QC Requirements, and Failure Modes
Time-savings data from HubSpot's State of Marketing 2026 and Gartner 2026 (as compiled by Cited) provides the empirical basis for the viability ratings below. These figures represent AI-assisted production versus fully manual production for practitioners with established workflows, not first-use estimates.
| Content Type | Automation Viability | Gross Time Savings | Primary Tool Category | Core QC Requirement | Primary Failure Mode |
|---|---|---|---|---|---|
| Long-form SEO content | Medium | ~67% (8.2 hrs → 2.7 hrs per 1,500-word post) | Long-form writing assistants, SEO brief tools | Fact-check every claim; SME spot-check; brand voice audit | Factual inaccuracy; generic structure; brand voice drift |
| Ad copy | High | High (variant generation at scale) | Copy generation tools, platform-native AI | Compliance scan; claim accuracy check; performance validation | Unsubstantiated superlatives; policy violations; voice inconsistency |
| Email copy | Medium–High | ~65% (12 hrs → 4.2 hrs per 10-email sequence) | Email-integrated AI, general LLMs | Personalization accuracy; deliverability check; brand tone review | Generic personalization tokens; flat prose rhythm; unverified claims |
| Social copy | High | ~70% (20 hrs → 6 hrs per 120-post calendar) | Social scheduling tools with AI, general LLMs | Brand voice spot-check; platform-specific format review | AI-tell phrasing; off-brand tone; platform format errors |
| Product / catalog descriptions | Very High | ~80% (15 hrs → 3 hrs per 50 items) | Catalog AI, e-commerce content tools | Accuracy against product spec; SEO attribute check | Spec hallucination; duplicate phrasing across SKUs; missing key attributes |
| Sales enablement assets | Low | ~60% (10 hrs → 4 hrs per case study equivalent) | General LLMs with heavy human direction | SME review; legal check; accuracy against deal context | Generic positioning; missing proprietary insight; brand voice drift |
Long-Form SEO Content
AI can accelerate the research synthesis, outline development, and first-draft stages of long-form content. The 67% time savings figure reflects a workflow where AI handles structural scaffolding and initial prose, with a human editor responsible for factual verification, original perspective, and brand voice alignment.
The primary failure mode is not hallucination alone — it is structural genericness. AI trained on web-average content produces web-average outlines. Without a strong content brief, competitive context, and brand intelligence as inputs before prompting, the output will be structurally similar to the top-ranking pages rather than differentiated from them. This is the context engineering problem: prompt refinement alone produces generic results without brand intelligence, audience models, and competitive context as inputs.
Content types within this category that are non-viable regardless of tool quality: executive thought leadership, original research, and proprietary analysis. AI cannot generate new data or replicate the judgment and experience that distinguishes genuine thought leadership from polished generic content.
Ad Copy
Ad copy is well-suited to AI generation because the task is inherently about variant production at scale — generating 30 headline options, testing multiple value proposition framings, or adapting a core message across audience segments. The constraint is not volume; it is compliance and claim accuracy.
AI-generated ad copy frequently produces unsubstantiated superlatives ("the best," "industry-leading," "guaranteed") and claim formulations that may not survive platform policy review or legal scrutiny. Every claim in ad copy that references a product benefit, competitive comparison, or performance outcome requires human verification before deployment.
Email Copy
Email sequences are a strong fit for AI-assisted drafting, particularly for nurture flows where the structural pattern is consistent and the volume of variants justifies the setup cost. The 65% time savings figure reflects sequence-level production, not individual one-off sends.
The primary QC requirement is personalization accuracy: AI-generated personalization tokens that reference incorrect contact attributes, company details, or behavioral triggers create a worse impression than no personalization at all. Brand tone review is also critical — email is a high-frequency touchpoint where voice drift compounds quickly across a sequence.
Social Copy
Social copy has the highest automation viability of the six types. The content unit is small, the volume is high, and the stakes of any individual post are relatively low. The 70% time savings figure for a 120-post calendar reflects this well.
The dominant failure mode is AI-tell phrasing — the detectable linguistic patterns that signal AI generation to readers: "delve into," "furthermore," "it's important to note," "in today's digital landscape," and similar constructions. These phrases are a direct symptom of brand voice drift and are detectable through a basic checklist review before publication.
Product and Catalog Descriptions
Product descriptions at catalog scale are the clearest case for AI automation. The task is structurally repetitive, the inputs are well-defined (SKU attributes, specifications, category context), and the output requirements are consistent. The 80% time savings figure — 15 hours reduced to 3 hours for 50 items — reflects this structural fit.
The critical QC requirement is accuracy against product specifications. AI will hallucinate product attributes — dimensions, compatibility, materials, certifications — when the input data is incomplete or ambiguous. Every generated description must be verified against the authoritative product record before publication.
Sales Enablement Assets
Sales enablement assets — battlecards, one-pagers, proposal sections, objection-handling guides — have the lowest automation viability of the six types. The content requires proprietary competitive intelligence, deal-specific context, and the kind of positioning judgment that AI cannot supply from general training data.
AI is useful for structural scaffolding and first-draft prose on templated formats (e.g., a standard one-pager layout), but the content that makes these assets effective — specific differentiation claims, accurate competitive comparisons, relevant customer proof points — must come from human sources and requires SME review before distribution.
Cross-Cutting Failure Modes: Brand Voice Drift and Compliance Gaps
Brand Voice Drift
Brand voice drift is the most consequential and most underestimated failure mode in AI content programs. It is distinct from hallucination: where hallucination produces factually wrong content, brand voice drift produces factually acceptable content that no longer sounds like the organization that published it.
The root cause is structural. Generative AI models are trained on averaged web language. Without explicit brand intelligence as a system input, every generation defaults toward that statistical average. The effect is subtle at first — one landing page reads slightly off, a product announcement introduces unapproved phrasing — but it compounds with production volume. As MagiHQ documents, the problem accelerates through "agent sprawl": when multiple AI workflows each carry their own forked version of a brand document, with no canonical source of truth, the outputs stop sounding like one company.
The scale of this problem is growing. Onely's analysis found that 74.2% of newly created webpages in April 2025 contained AI text. As AI-generated content floods the web, models trained on that content will increasingly reflect averaged AI output rather than averaged human writing — accelerating the homogenization problem for any team that does not actively counteract it.
Prompt refinement alone does not fix brand voice drift. The solution is a calibration system: a canonical brand source of truth that is accessible to AI workflows (not just a PDF referenced manually), voice training using representative content examples, and periodic calibration reviews. The Content Marketing Institute's 2026 data shows that organizations using brand voice training — uploading five to ten representative content examples — reduced revision rates from 41% to 18%.
Detectable symptoms of brand voice drift include:
- AI-tell phrases: "delve," "furthermore," "it's important to note," "in today's digital landscape," "at its core," "game-changing"
- Flat, even prose rhythm without the variation characteristic of a specific writer or brand
- Generic structural patterns (problem → solution → benefit) without brand-specific framing
- Vocabulary that is correct but not the organization's vocabulary — synonyms where the brand uses specific terms
- Unsupported superlatives and hedging constructions that the brand's style guide would reject
Hallucination
Hallucination — the generation of plausible but factually incorrect content — occurs at a rate of 12–18% in AI-generated marketing claims, ranging from 11.8% for GPT-4 to 18.3% for Claude 2, according to the Stanford HAI 2024 AI Index Report. The highest-risk content categories are statistics, dates, product specifications, and competitive comparisons. For a detailed breakdown of hallucination mechanics, detection patterns, and mitigation steps by content type, see AI Hallucination Risks in Marketing Content Generation.
Compliance Gaps
Regulated industries face a structural constraint that reduces the practical value of AI content generation. Healthcare, financial services, and legal services organizations achieve only 25–30% net time savings from AI content — compared to approximately 60% in unregulated sectors — because mandatory compliance review consumes the time that AI generation saves. The automation viability ratings in this guide assume unregulated content; adjust them downward for any content category that requires legal or compliance review before publication.
Automation Decision Matrix: Conditions for Viable AI Generation by Content Type
The viability of AI generation for any specific content type depends on five conditions. The matrix below maps each condition against the six content types to produce a structured decision framework. Ratings synthesize the automate/human-led/human-only breakdowns from Onely and content type suitability data from Cited.
| Condition | Long-Form SEO | Ad Copy | Email Copy | Social Copy | Product Descriptions | Sales Enablement |
|---|---|---|---|---|---|---|
| Content volume (high favors automation) | Low–Med | High ✓ | Med–High ✓ | High ✓ | Very High ✓ | Low |
| Brand voice sensitivity (high requires calibration system first) | High | Medium | High | High | Medium | Very High |
| Regulatory exposure (requires human-led or human-only) | Low | Medium | Low–Med | Low | Low–Med | Medium |
| Factual complexity (statistics, dates, competitive claims) | High | Medium | Low–Med | Low | Medium | High |
| Originality requirement (proprietary insight non-viable) | Medium–High | Low | Low | Low | Low | High |
| Recommended approach | Human-led | Automate | Automate | Automate | Automate | Human-led |
Two practical thresholds determine when to move from human-led to automate:
- Volume threshold: When manual production time exceeds 10 hours per month for a single content type, the setup cost of an AI workflow with proper QC is typically justified within 4–6 weeks.
- Brand calibration threshold: When fewer than five representative on-brand content examples are available to train or prompt the model, do not automate brand-sensitive content types until that foundation exists. The 65% of organizations that lack AI-ready brand data (McKinsey 2025) are not ready to automate high-sensitivity content types.
Tiered QC Checklist: Review Steps by Content Risk Level
Uniform review across all AI-generated content is inefficient. A social post and a regulated financial services email have fundamentally different risk profiles. The three-tier framework below organizes review requirements by content risk level rather than content type — though the mapping between types and tiers is consistent.
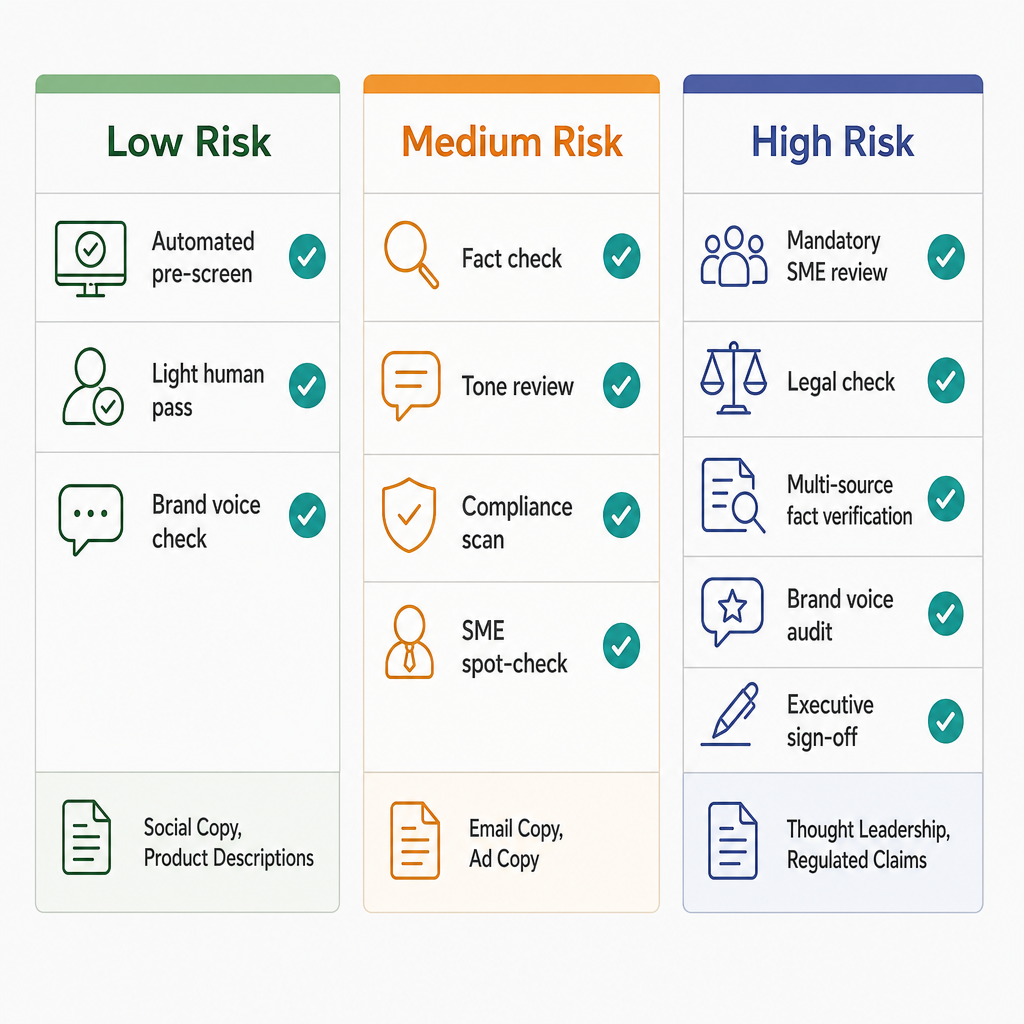
Tier 1: Low Risk / High Volume
Applies to: social copy, product descriptions, email subject lines, meta descriptions, ad headline variants.
- Automated pre-screening: Run output through an AI-tell phrase checker and a basic brand vocabulary filter before human review.
- Accuracy spot-check: Verify any product attributes, dates, or specific claims against the source record. For product descriptions, check against the authoritative product spec.
- Brand voice pass: Light human read for tone and vocabulary. Flag AI-tell phrases and off-brand constructions. Estimated time: 5–10 minutes per batch.
- Format validation: Confirm output meets platform character limits, format requirements, and any channel-specific constraints.
Tier 2: Medium Risk
Applies to: blog posts, email campaign copy, ad copy with specific claims, landing page sections.
- Fact verification: Check every statistic, date, product claim, and competitive reference against a primary source. Estimated time: 10–15 minutes per 500 words (per Cited's QC benchmark data).
- Brand voice audit: Full read for tone, vocabulary, and structural patterns. Replace AI-tell phrases. Verify the content sounds like the brand, not like averaged web content. Estimated time: 5–10 minutes per piece.
- Compliance scan: Review for unsubstantiated claims, superlatives, and any content that may trigger platform policy review or legal scrutiny.
- SME spot-check: For content in specialized domains (technical products, regulated services, competitive positioning), route to a subject-matter expert for accuracy confirmation.
- Link and source validation: Verify all cited sources are current and accurately represented. Estimated time: 3–5 minutes per piece.
Tier 3: High Risk / Low Volume
Applies to: thought leadership, executive communications, regulated claims (medical, financial, legal), competitive comparisons, crisis communications, original research summaries.
- Mandatory SME review: Full read by a subject-matter expert with sign-off authority. No exceptions for content with factual complexity or domain specificity.
- Legal check: Route all regulated claims, competitive comparisons, and any content with liability exposure to legal review before publication.
- Multi-source fact verification: Every factual claim verified against at least two independent primary sources. Document the verification trail.
- Brand voice audit: Full structural and linguistic review against brand guidelines. Thought leadership in particular must reflect genuine organizational perspective, not AI-averaged positioning.
- Executive sign-off: For content published under an executive's name or representing organizational positions, final approval from the named author or their delegate.
Governance Notes: Disclosure, Regulated Content, and Review Ownership
Disclosure Requirements
AI content disclosure requirements are active and expanding. The EU AI Act includes provisions for AI-generated content transparency. Several US states have enacted or are implementing disclosure requirements for AI-generated content in specific contexts, including California and Colorado. For marketing practitioners, the practical question is not whether disclosure will be required in some contexts — it will — but whether your current content production and publication workflow can identify which pieces are AI-generated when disclosure is required.
The minimum governance requirement is a production log that records which content was AI-generated, which model was used, and what human review steps were applied. This is a foundational record-keeping requirement, not an optional practice.
Regulated Content Boundaries
Certain content categories require mandatory compliance review regardless of content type, automation viability rating, or QC tier:
- Medical and health claims — any content that describes treatment efficacy, drug interactions, diagnostic criteria, or health outcomes
- Financial services claims — investment performance representations, rate disclosures, product suitability statements
- Legal services — any content that could constitute legal advice or create professional liability
- Children's content — subject to COPPA and equivalent regulations in multiple jurisdictions
- Comparative advertising — claims that directly name competitors or compare specific product attributes
As noted earlier, regulated industries achieve only 25–30% net time savings from AI content generation versus approximately 60% in unregulated sectors, because compliance review is non-negotiable and consumes a significant portion of the time AI generation saves.
Review Ownership
The most common governance failure in AI content programs is ambiguous review ownership: AI generates content, multiple people make light edits, and no one has clear accountability for publication approval. At scale, this produces the brand drift and compliance exposure problems described above.
Each content type should have a named review owner for each QC tier. That owner is accountable for the review steps in their tier and for the publication decision. This is not a bureaucratic requirement — it is the mechanism that prevents AI content programs from becoming, as MagiHQ describes it, "lots of automations running with partial context and unclear ownership, reducing trust and making publishing feel like roulette."


Comments
Join the discussion with an anonymous comment.